
Problem
Assessing large volumes of image-based data manually is time-consuming and inconsistent, especially under fatigue or when images are blurred. Traditional OCR methods often fail to generalize across lighting, orientation, and image quality variations commonly found in field conditions.
In this project, the main challenge was:
- Handling low-resolution, variably lit, and occluded numeric images.
- Minimizing human intervention and manual validation.
- Integrating AI inference into an accessible web interface.
Solution
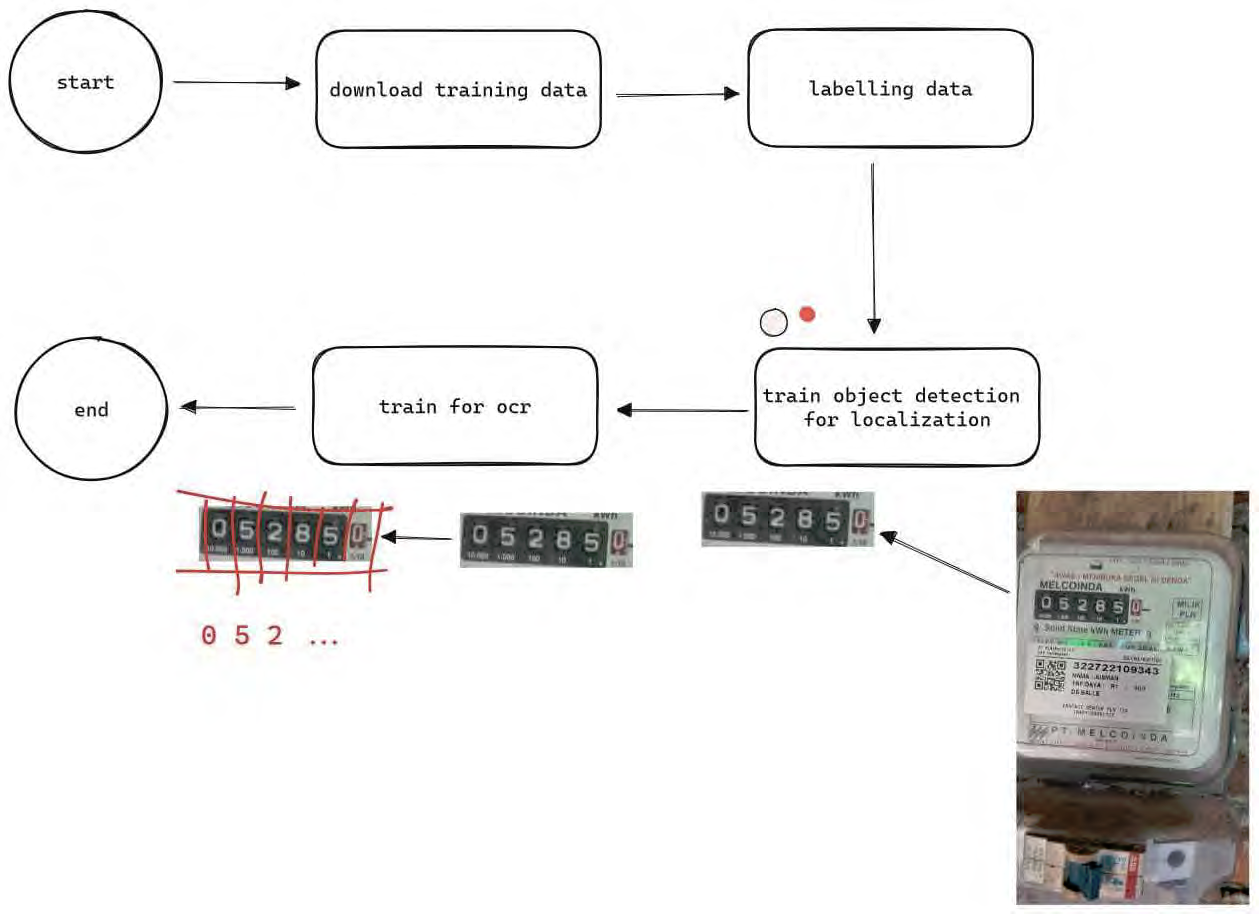
The solution integrates a custom-trained YOLOv8 model for object detection and number localization, paired with a Streamlit-based web interface for easy user interaction. Using RoboFlow for dataset preparation and augmentation, the model achieves consistent accuracy even on imperfect real-world samples.
Workflow Highlights:
- Data collection and cleaning from field images of electricity meters.
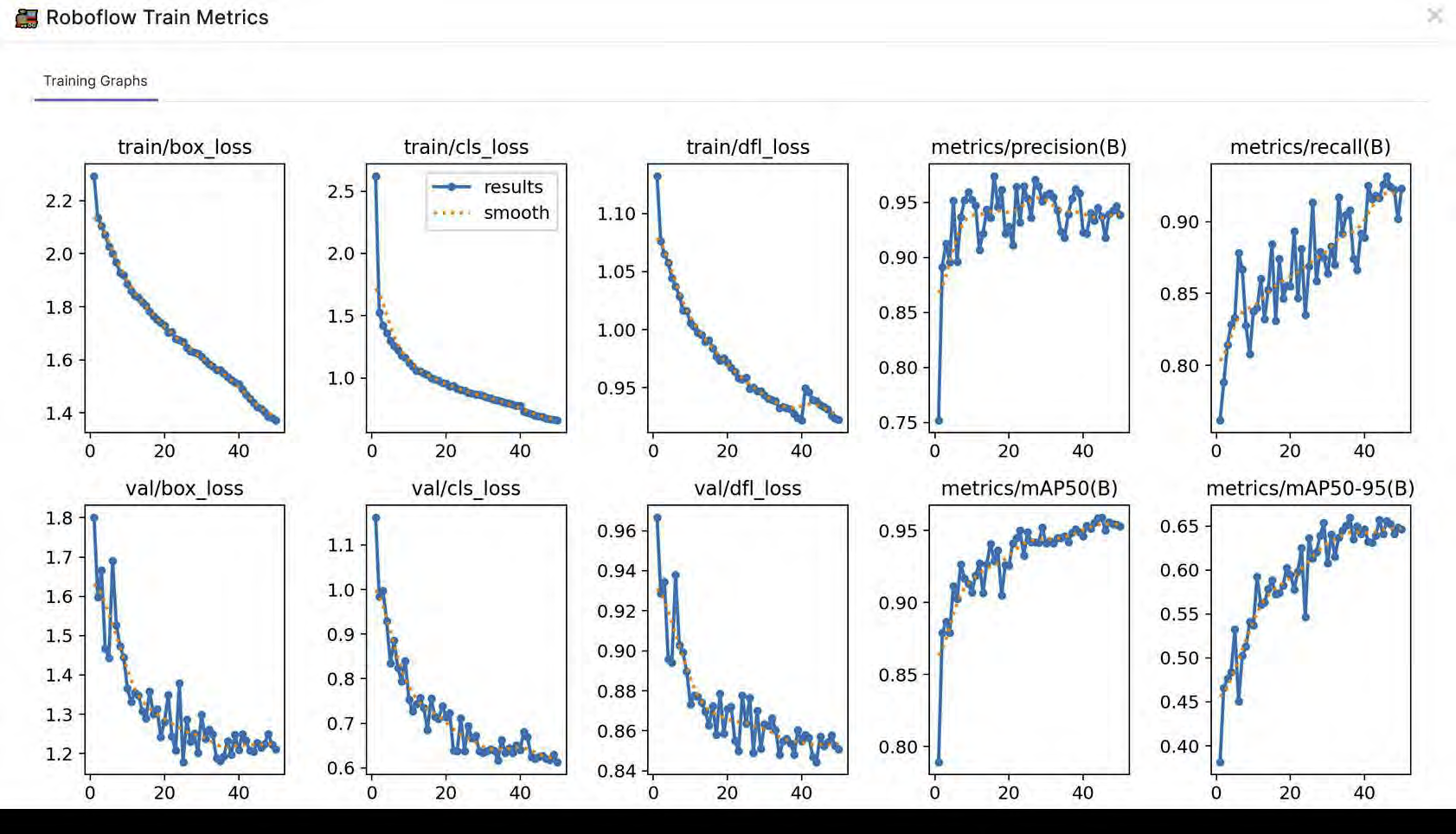
- Model training using YOLOv8 with metrics monitoring for precision, recall, and validation loss.
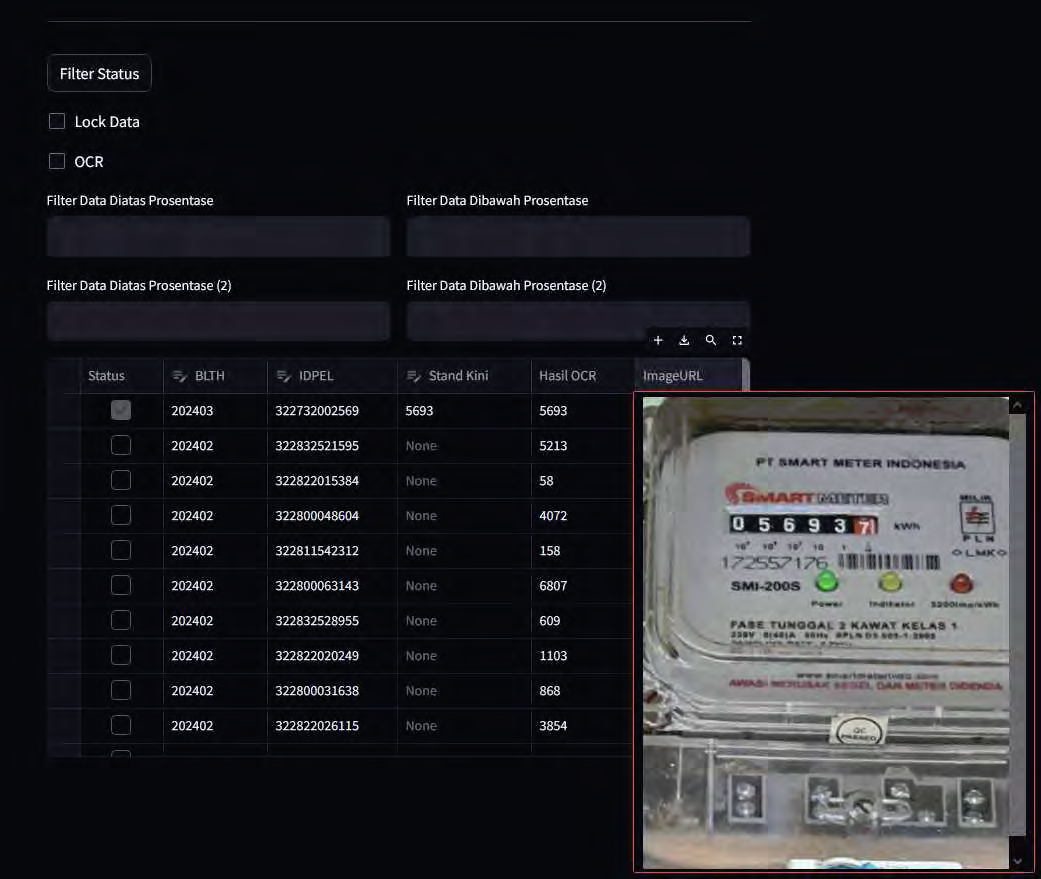
- Real-time inference served via Streamlit, displaying predictions and confidence scores.
- Automated reading logs stored for further analysis or export.
tldr
- Situation: Manual reading of numeric data from field images led to fatigue and inconsistent results.
- Task: Automate and standardize the process using machine learning.
- Action: Built and trained a YOLOv8-based OCR model; integrated it into a Streamlit web app.
- Result: Achieved >98% accuracy on validation data, reducing human input and error.
Technical Highlights
- Model: YOLOv8 trained on numeric and text detection dataset.
- Frameworks: Python, PyTorch, Streamlit.
- Data Pipeline: Roboflow for annotation and augmentation.
- Metrics: Precision–Recall analysis; training/validation losses tracked.
- Deployment: Model embedded in a web-based UI for non-technical users.

Reflection
This project emphasized the practical power of AI-assisted automation in solving tedious visual data problems. Embedding the trained model in a simple web interface made it usable by non-technical operators, proving how machine learning can bridge operational and technical workflows.
Future improvements could include:
- Text-region post-processing (e.g., digit alignment correction).
- Support for multilingual text recognition.
- Integration with APIs for automatic data logging and analytics dashboards.